डेटा और डेटा विज्ञान का परिचय
भूमिका
डेटा साइंस अध्ययन और अभ्यास का एक क्षेत्र है जिसका उद्देश्य डेटा से ज्ञान और जानकारी निकालना है। ऐसा करने के लिए वैज्ञानिक विधियों, प्रक्रियाओं, सांख्यिकी, गणित और डोमेन ज्ञान का उपयोग किया जाता है, निश्चित रूप से कम्प्यूटेशनल शक्ति का उपयोग करते हुए। हालाँकि यह शब्द हाल के वर्षों में गढ़ा गया और लोकप्रियता हासिल की, किसी को यह जानकर आश्चर्य हो सकता है कि डेटा विज्ञान में उपयोग की जाने वाली अवधारणाएँ सदियों पुरानी हैं। ऐसे में यह पूछना स्वाभाविक है कि यह आज इतना लोकप्रिय क्यों हो गया।
इसने दो चीजों के कारण लोकप्रियता हासिल की। एक, हमने डेटा जमा करना शुरू कर दिया, जैसा पहले कभी नहीं हुआ। अधिक डेटा का अर्थ है अधिक जानकारी निकालने की संभावना। और अधिक जानकारी निर्णय लेने में मदद करती है। और हम इस अवसर का लाभ उठाना चाहते हैं।
हालांकि, इस विशाल मात्रा में डेटा ने अपने आप में उछाल का कारण नहीं बनाया। अधिक डेटा का अर्थ है अधिक गणना। जब हम डेटा की हजारों पंक्तियों के बारे में बात करते हैं, तो यह मानव की क्षमता से परे है कि वह आवश्यक गणना मैन्युअल रूप से कर सके। और जब लाखों या अरबों पंक्तियों की बात करें, तो कुछ दशक पहले एक मशीन (कंप्यूटर) को इसे करने में कई दिन लग गए होंगे। आज, हालांकि, कम्प्यूटेशनल शक्ति में तेजी से वृद्धि हुई है। और यह, बड़ी मात्रा में डेटा के साथ, यह सुनिश्चित करता है कि हमारे पास तेल (डेटा) और रिग (कम्प्यूटेशनल पावर) है।
डेटा के बारे में
डेटा, जैसा कि पिछले खंड में बताया गया है, डेटा विज्ञान में सबसे आवश्यक तत्व है। वे किसी घटना, किसी व्यक्ति या किसी चीज़ की जानकारी या विशेषताएँ प्रदान करते हैं। इसे अवलोकन, निगरानी आदि के माध्यम से एकत्र किया जाता है। इसे रखने का एक तरीका डेटा स्टोर है जो क्या, कब, कहां और कौन के बारे में जानकारी संग्रहीत करता है। और विश्लेषक और डेटा वैज्ञानिक इसका इस्तेमाल ‘क्यों’ और ‘कैसे’ ढूंढते हैं।
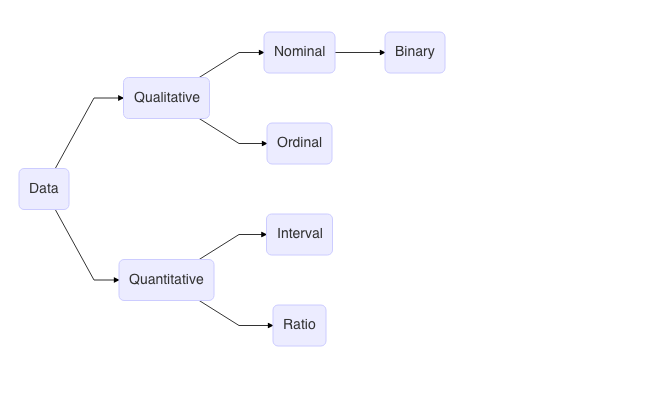
डेटा के प्रकार
डेटा गुणात्मक या मात्रात्मक हो सकता है। गुणात्मक का अर्थ है गैर-संख्यात्मक और मात्रात्मक का अर्थ है संख्यात्मक। मात्रात्मक डेटा को आगे असतत और निरंतर में विभाजित किया जा सकता है।
असतत पूर्ण संख्याओं को इंगित करता है। उदाहरण के लिए 1 सेब, 25 लोग वगैरह। जब हम 1 सेब के बारे में बात करते हैं, तो यह बिल्कुल एक होता है। और यह समय में 0.8 या 1.25 या 2 भी नहीं बनता है। दूसरी ओर निरंतर पूर्ण संख्या नहीं है। ऊपर बताए गए 1 सेब का वजन 100 ग्राम हो सकता है। यह १०० ग्राम कभी भी ठीक १०० ग्राम नहीं होता। मान लीजिए, 99 ग्राम और 101 ग्राम या 99.9 ग्राम और 100.1 ग्राम आदि के बीच है। एक tolerance शामिल हैं। इसी तरह, किसी व्यक्ति का वजन या वाहन की गति भी निरंतर चर के उदाहरण हैं। ये दोनों समय के साथ बदलते हैं।
माप के पैमाने के आधार पर डेटा को वर्गीकृत करने का एक और तरीका है यानी डेटा पर अंकगणित को लागू करने का कितना अर्थ है। नाममात्र(Nominal) डेटा श्रेणीबद्ध/गुणात्मक डेटा का एक प्रकार है जहां चर के सभी गुणों का समान महत्व है। उदाहरण के लिए लिंग (M/F/MtF/FtM/Others) या स्थान (मुंबई, न्यूयॉर्क, सिंगापुर, लंदन, टोक्यो) या प्रतिक्रिया (हां, नहीं)। नाममात्र डेटा का एक प्रकार बाइनरी है जहां बाइनरी प्रतिक्रियाएं शामिल हैं (हां/नहीं, 0/1 आदि)। नाममात्र चर के क्रम का कोई मतलब नहीं है (वर्णानुक्रम के अलावा, शायद)। साधारण(Ordinal) डेटा भी श्रेणीबद्ध डेटा है। लेकिन चर के गुणों का असमान महत्व है। उदाहरण के लिए छोटा, मध्यम, बड़ा या निचला, मध्य, ऊपरी आदि। क्रमिक चर का क्रम समझ में आता है। अंतराल(Interval) डेटा एक संख्यात्मक डेटा है, जो ज्यादातर रेटिंग पैमानों से उत्पन्न होता है, उदाहरण के लिए, सर्वेक्षणों में। उदाहरण के लिए [Linkert Scale)(https://en.wikipedia.org/wiki/Likert_scale) जहां एक दर कहने के मामले में, दृढ़ता से सहमत, सहमत, तटस्थ, असहमत, पूरी तरह से असहमत। इनमें से प्रत्येक का एक अंतर्निहित मूल्य है। तो, दृढ़ता से सहमत 1 हो सकता है, सहमत 2 हो सकता है और इसी तरह। इसमें एक महत्वपूर्ण पहलू शून्य उत्पत्ति नहीं है। इसलिए, इस प्रकार के पैमाने में यह नहीं कहा जा सकता है कि 2, 1 से दोगुना अधिक महत्वपूर्ण है। अनुपात (Ratio) डेटा वास्तविक संख्या दर्शाता है। सभी वास्तविक संख्याएँ अनुपात डेटा हैं। इसमें शून्य मूल सहित संख्याओं के सभी गुण हैं।
आप भी वीडियो पर एक नजर डाल सकते हैं।