সংক্ষিপ্তসার ডেটা
কেন আমাদের অনুসন্ধান বিশ্লেষণ এবং ডেটা সংক্ষিপ্তসার প্রয়োজন
মনে করুন যে আপনার কাছে কোনও বিদ্যালয়ের 1000 শিক্ষার্থীর ওজনের তথ্য রয়েছে। এ থেকে যে কোনও কিছু বোঝার একটি উপায় হ’ল প্রতি টা সারি র তথ্য এক এক করে পড়া । যেমন আপনি যদি এই 1000 টি ওজনের মধ্যে সর্বনিম্ন ওজন কী তা জানতে চান তবে আপনি প্রতি সারি র ডেটার তুলনা শুরু করতে পারেন। তবে, সেটা কি খুব একটা প্রজ্ঞ ? অবশ্যই না. বা, আপনি যদি raw তথ্য থেকে কোনও অন্তর্দৃষ্টি পেতে চান, তথ্য অন্বেষণ না করেও কি এটি সম্ভব? অবশ্যই না. এবং এজন্য আমাদের ডেটা সংক্ষিপ্ত (Summarize ) করে এটিকে অন্বেষণ করা প্রয়োজন; সহজেই ব্যাখ্যা করা যায় এমন তথ্য সন্ধান করতে।
শ্রেণিবদ্ধ ভ্যারিয়েবল সংক্ষিপ্ত করা
ডেটা র বিভন্ন প্রকারের বিষয়ে জানতে এই লেখা টি পড়ুন ।
শ্রেণীবদ্ধ ভ্যারিয়েবল শুধু মাত্র গোনা সম্ভব। তারপরে আমরা ফলাফলটি নিখুঁত সংখ্যায় বা শতাংশে দেখাই। যেমন 5 লাল বল, 2 নীল বল এবং 3 সবুজ বল বা 50% লাল বল, 20% নীল বল এবং 30% সবুজ বল। আমরা ফলাফলটি একটি টেবিল হিসাবে দেখাতে পারি। অথবা আমরা এটি গ্রাফ হিসাবে দেখাতে পারি।পারি।
x<-read.csv("https://query.data.world/s/ycimehoogc3wiwgkd65z7d24v6mqik", header=TRUE, stringsAsFactors=FALSE)
names(x)[1]<-"EnglishSpeaker"
names(x)[6]<-"ClassAttribute"
names(x)[4]<-"Semester"
x$EnglishSpeaker<-as.factor(x$EnglishSpeaker)
x$Semester<-as.factor(x$Semester)
x$ClassAttribute<-as.factor(x$ClassAttribute)
x<- x %>%
mutate(EnglishSpeaker=ifelse(EnglishSpeaker==1,"yes","no"))%>%
mutate(ClassAttribute=case_when(ClassAttribute==1 ~ "low",
ClassAttribute==2 ~ "medium",
ClassAttribute==3 ~ "high"))%>%
mutate(Semester=ifelse(Semester==1, "Summer", "Regular"))%>%
select(1,4,6)
x%>%
group_by(ClassAttribute)%>%
summarise(Count=n())%>%
mutate(CountPercent=Count/sum(Count))%>%
ggplot(aes(y=Count,
x = reorder(ClassAttribute,Count),
)
)+
geom_col(width = 0.5,fill='turquoise')+
geom_text(aes(y=Count-6, label=Count), color="white", size=10)+
labs(title = "Class Attribute",
subtitle = "Teaching assistant evaluation",
x="Attribute",
y="Count",
caption = "Source: UCI machine learning repository")+
theme_clean() +
annotation_custom(l, xmin = 2.7, xmax = 4, ymin = 50, ymax = 63) +
coord_cartesian(clip = "off")
আমরা যখন একটি ভেরিয়েবলের সংক্ষিপ্তসার করি তখন ইটা সম্ভব । একাধিক শ্রেণীবদ্ধ ভ্যারিয়েবল হলে কী হবে? তখন ও , আমরা টেবিল হিসাবে বা নীচের মত বিভিন্ন ধরণের বার চার্ট হিসাবে প্রদর্শন করতে পারি। আর সেটা করি দুটি ভ্যারিয়েবল যুক্ত করে তারপর গুনে ।
x%>%
group_by(EnglishSpeaker)%>%
summarise(low=sum(ClassAttribute=="low"), medium=sum(ClassAttribute=="medium"), high=sum(ClassAttribute=="high"))%>%
tidyr::gather("ClassAttribute","Count",-1)%>%
ggplot(aes(x=EnglishSpeaker, y=Count, fill=ClassAttribute))+
geom_col(position="dodge2")+
geom_text(aes(y=Count-2, label=Count),
position = position_dodge(width = 1
),
color="white",
size=5
)+
labs(title = "Class Attribute by native language",
subtitle = "Teaching assistant evaluation",
x="English Speaker",
y="Count",
caption = "Source: UCI machine learning repository")+
theme_clean() +
annotation_custom(l, xmin = 2, xmax = 3.4, ymin = 36, ymax = 52) +
coord_cartesian(clip = "off")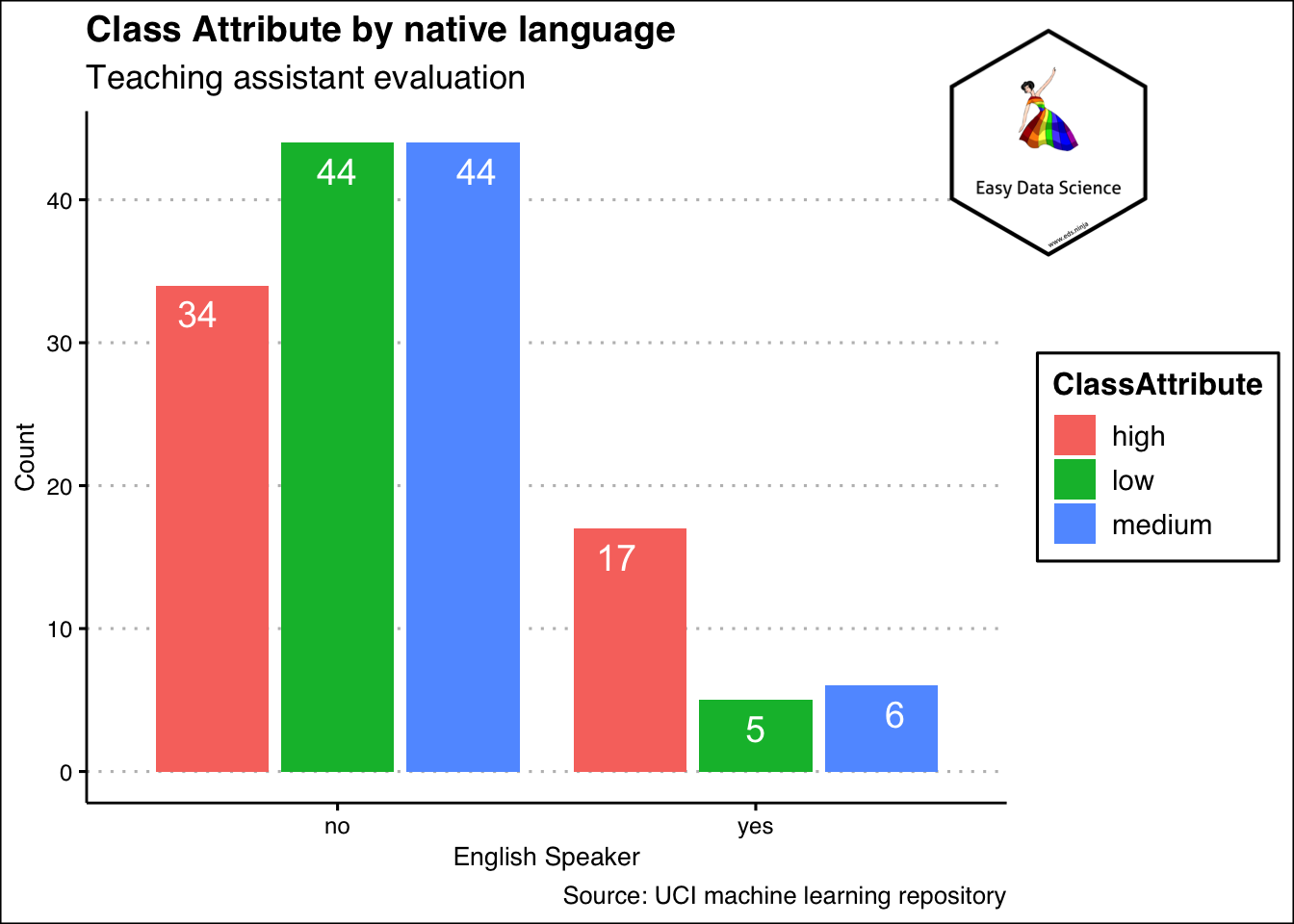
কখনও কখনও, এই এক ই তথ্য নীচের চিত্রের মতো দেখানো উপকারী হতে পারে। অনুগ্রহ করে লক্ষ্য করুন যে y এক্সিস 1 অবধি করা হয়েছে এবং হ্যাঁ এবং না উভয়ই সমান উচ্চতা অবধি আঁকা । মানে এই গ্রাফ এ আমরা কটা হ্যাঁ বা কটা না দেখছি না । বরং দেখছি যে হ্যাঁ বা না এর মধ্যে ছোট , বড়ো আর মাঝারি র অবদান কত ।
x%>%
group_by(EnglishSpeaker)%>%
summarise(low=sum(ClassAttribute=="low"), medium=sum(ClassAttribute=="medium"), high=sum(ClassAttribute=="high"))%>%
tidyr::gather("ClassAttribute","Count",-1)%>%
ggplot(aes(x=reorder(EnglishSpeaker,Count),
y=Count, fill=ClassAttribute))+
geom_col(position="fill", width = 0.5)+
geom_text(aes(label=Count),
position = position_fill(vjust = 0.5),
color="white",
size=5
)+
labs(title = "Class Attribute by native language",
subtitle = "Teaching assistant evaluation",
x="English Speaker",
y="Count",
caption = "Source: UCI machine learning repository")+
theme_clean() +
annotation_custom(l, xmin = 2, xmax = 3.4, ymin = 0.8, ymax = 1.2) +
coord_cartesian(clip = "off")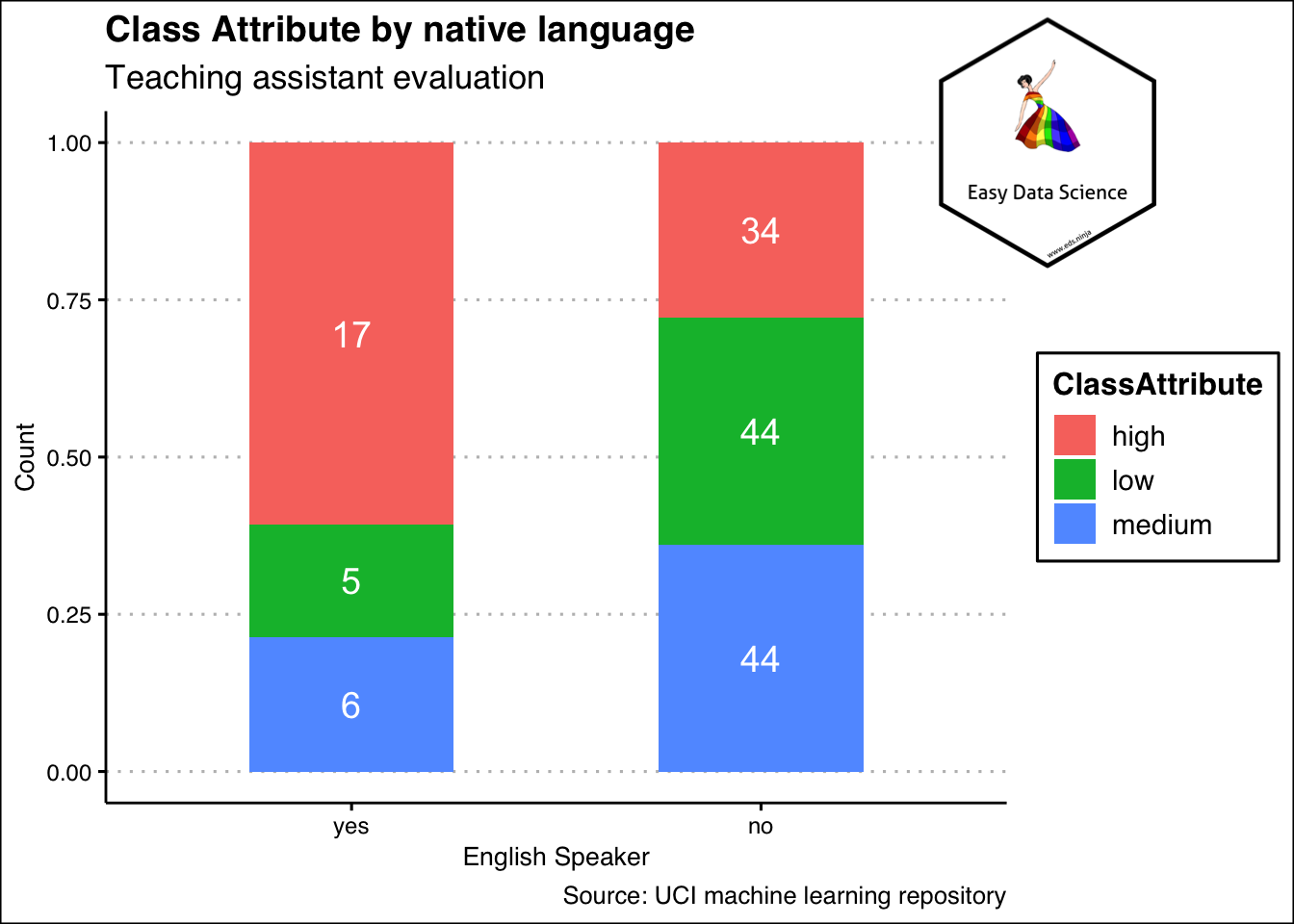
শ্রেণিবদ্ধ ভেরিয়েবলের ক্ষেত্রে, আমরা উপস্থিতির সংখ্যা গণনা করি। যদি একাধিক ভেরিয়েবল জড়িত থাকে তবে আমরা ভেরিয়েবলগুলির সংমিশ্রণটি গণনা করি।
সংখ্যার ভেরিয়েবলগুলির সংক্ষিপ্তকরণ
একক ভেরিয়েবল
শ্রেণিবদ্ধ ভেরিয়েবলের মতো , সংখ্যার ভেরিয়েবলগুলি গণনা করাও সম্ভব। সাধারণত, গণনাটি কিছুটা আলাদা। আমরা বিনগুলি তৈরি করি এবং বিনগুলি গণনা করি। উদাহরণস্বরূপ, যদি আমাদের 200 ব্যক্তির ওজন থাকে যা 50 কেজি থেকে 100 কেজি অবধি হয়, আমরা 50 কেজি থেকে 59 কেজি, 60 কেজি থেকে 69 কেজি ইত্যাদি বিন তৈরি করতে পারি। এগুলিকে বিন বলা হয়। এবং তারপরে আমরা সেই বিনের মধ্যে সংঘটিত ডাটা পয়েন্টগুলির সংখ্যা দেখাই, আমরা তা টেবিলে বা গ্রাফ হিসাবে প্রদর্শন করতে পারি।
df <- data.frame(
sex=factor(rep(c("F", "M"), each=200)),
weight=round(c(rnorm(200, mean=40, sd=4), rnorm(200, mean=50, sd=5)))
)
ggplot(df, aes(x=weight)) +
geom_histogram(binwidth=1, color="black", fill="blue", alpha=0.3)+
labs(title="Histogram of weight",
y="frequency")+
theme_clean()+
annotation_custom(l, xmin = 60, xmax = 65, ymin = 22, ymax = 30) +
coord_cartesian(clip = "off")
হিস্টোগ্রাম থেকে বেশিরভাগ শিক্ষার্থীর ওজন কত (আন্দাজমত) তা বোঝা খুব সহজ হয়ে যায়। তথ্যটি দেখার আরেকটি উপায় হ’ল ঘনত্বের (density ) প্লট ব্যবহার করা।
ggplot(df, aes(x=weight)) +
geom_density(alpha=.2, fill="#FF6666")+
labs(title="Density of weight")+
theme_clean()+
annotation_custom(l, xmin = 60, xmax = 65, ymin = 0.045, ymax = 0.06) +
coord_cartesian(clip = "off")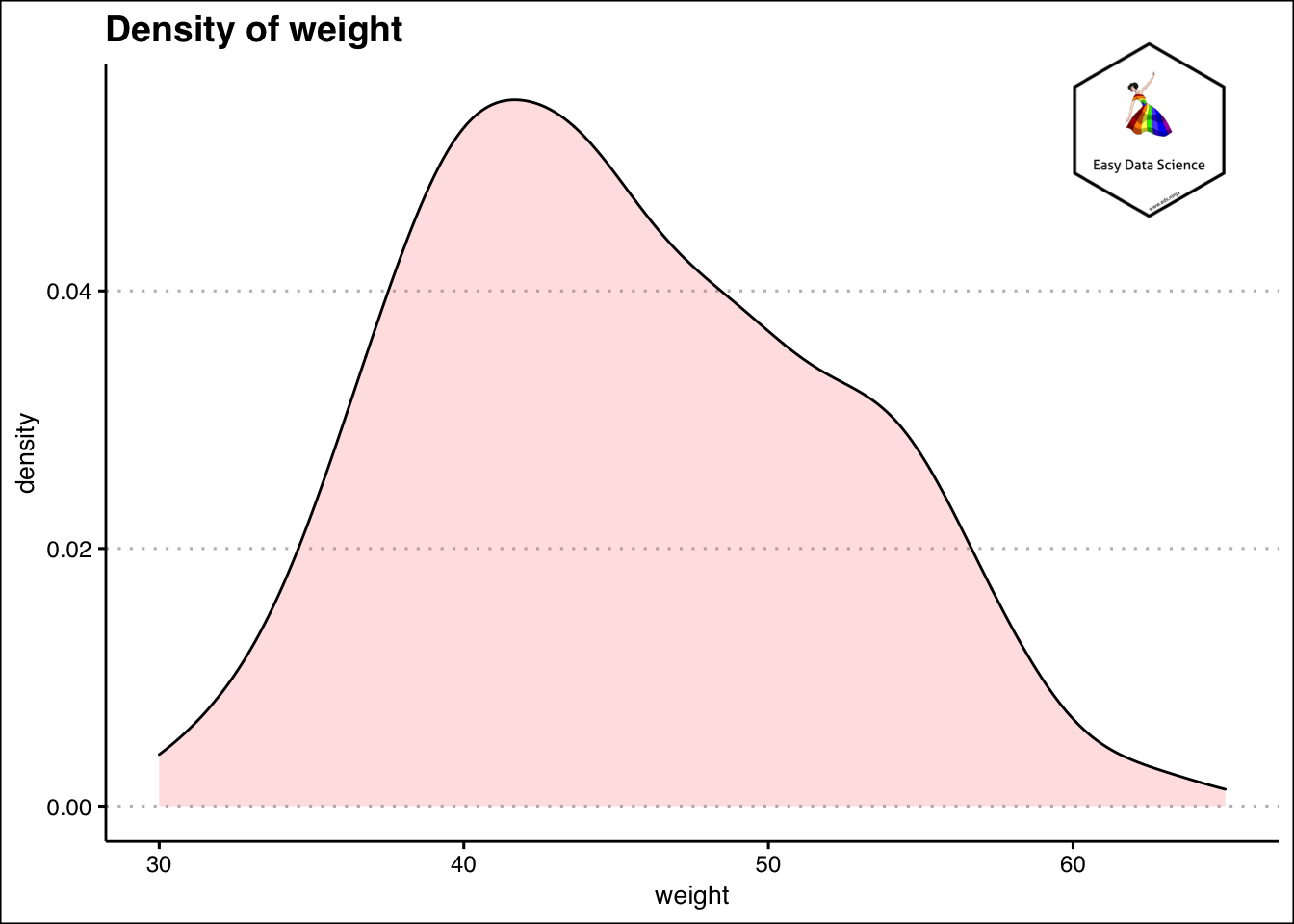
একক ভেরিয়েবলের সংক্ষিপ্তসার করার আরেকটি উপায় হ’ল সংঘটিত ফ্রিকোয়েন্সি (Cumulative ) ব্যবহার করা। এটি ভেরিয়েবলের বিনগুলি তৈরি করে এবং সেগুলি ক্রমে রেখে তারপরে ক্রমযুক্ত ঘটনা বা ডেটা পয়েন্ট গণনা করা হয়। একটি উদাহরণ নীচে প্রদর্শিত।
df%>%
mutate(weight=case_when(
weight<40 ~ "30-39",
weight>=40 & weight<50 ~ "40-49",
weight>=50 & weight<60 ~ "50-59",
weight>=60 ~ "60-69"
))%>%
group_by(weight)%>%
summarise(Count=n())%>%
mutate(cumulative_count=cumsum(Count))%>%
mutate(cumulative_percent=cumulative_count*100/sum(Count)) %>%
knitr::kable()| weight | Count | cumulative_count | cumulative_percent |
|---|---|---|---|
| 30-39 | 87 | 87 | 21.75 |
| 40-49 | 202 | 289 | 72.25 |
| 50-59 | 105 | 394 | 98.50 |
| 60-69 | 6 | 400 | 100.00 |
“নির্দিষ্ট মানের তুলনায় কতজন কম বা কতজন বেশি” এরকম প্রশ্নের উত্তর দেওয়ার চেষ্টা করার সময় এটি বিশেষত কার্যকর।
df%>%
mutate(weight=case_when(
weight<40 ~ "30-39",
weight>=40 & weight<50 ~ "40-49",
weight>=50 & weight<60 ~ "50-59",
weight>=60 ~ "60-69"
))%>%
group_by(weight)%>%
summarise(Count=n())%>%
mutate(cumcount=cumsum(Count))%>%
mutate(cumper=cumcount*100/sum(Count))%>%
ggplot(aes(x=weight, y=cumper, group=1))+geom_line(color="black")+geom_point()+
labs(title="Cumulative Percentage of Weight(Range)",
x="Weight Ranges",
y="Cumulative Percentage (%)")+
theme_clean() +
annotation_custom(l, xmin = 3, xmax = 4, ymin = 40, ymax = 60) +
coord_cartesian(clip = "off")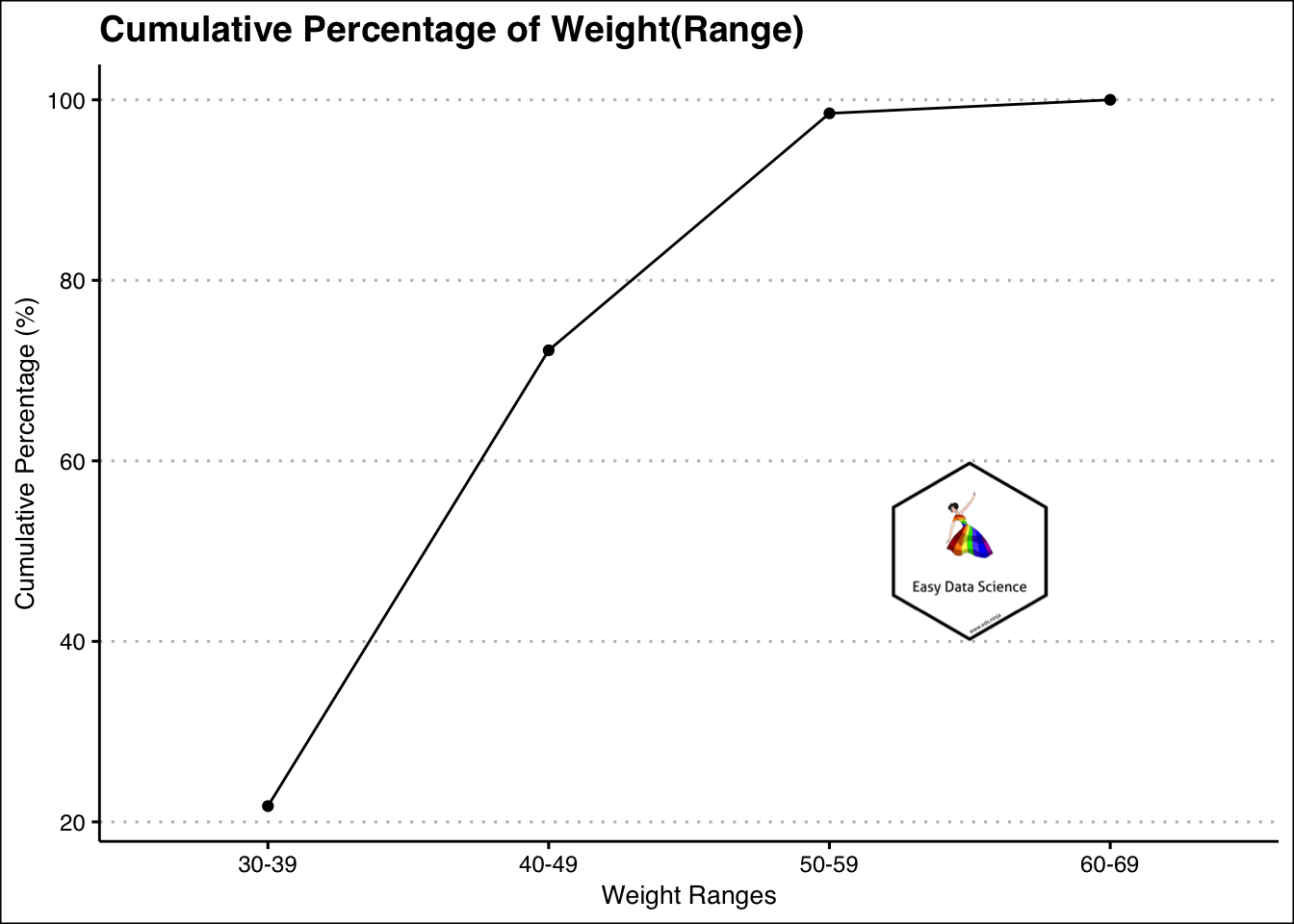
উদাহরণস্বরূপ, উপরের গ্রাফ থেকে এটি স্পষ্ট হয় যে বেশিরভাগ ওজন 59 কেজি থেকে কম বা সমান।
সংখ্যাসূচক এবং শ্রেণিবদ্ধ ভেরিয়েবলের সংমিশ্রণ
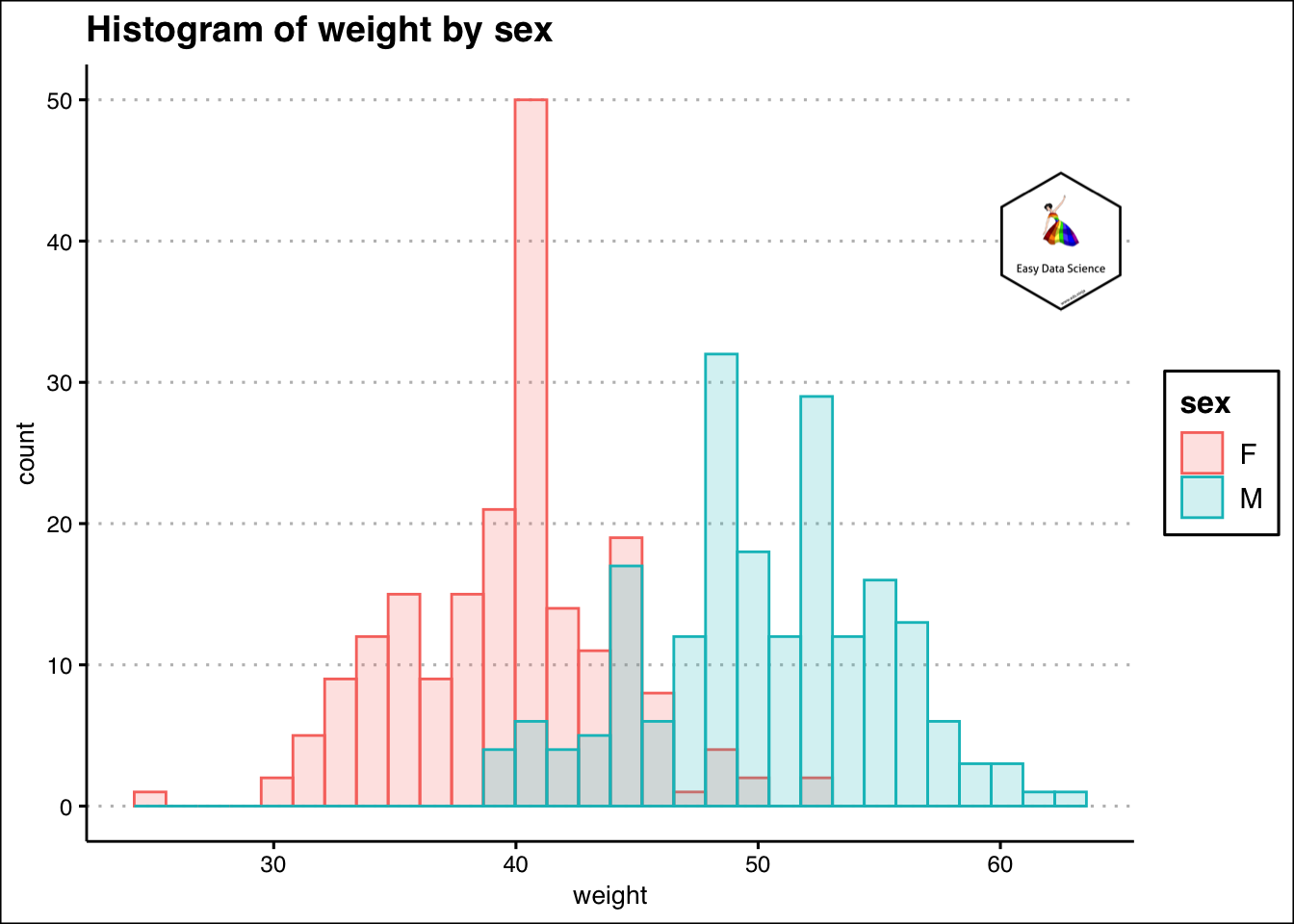
কখনও কখনও সংখ্যাসূচক এবং শ্রেণিবদ্ধ ভেরিয়েবলের সংমিশ্রণ থাকতে পারে। পূর্ববর্তী উদাহরণ থেকে, আমরা যদি লিঙ্গ অনুসারে শিক্ষার্থীদের ওজন পরীক্ষা করতে চাই, তবে আমরা হিস্টোগ্রামের ওভারলায়িং (overlaying ) প্লট করতে পারি।
ggplot(df, aes(x=weight, color=sex, fill=sex)) +
geom_histogram(alpha=0.2, position="identity")+
labs(title="Histogram of weight by sex")+
theme_clean()+
annotation_custom(l, xmin = 60, xmax = 65, ymin = 35, ymax = 45) +
coord_cartesian(clip = "off")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.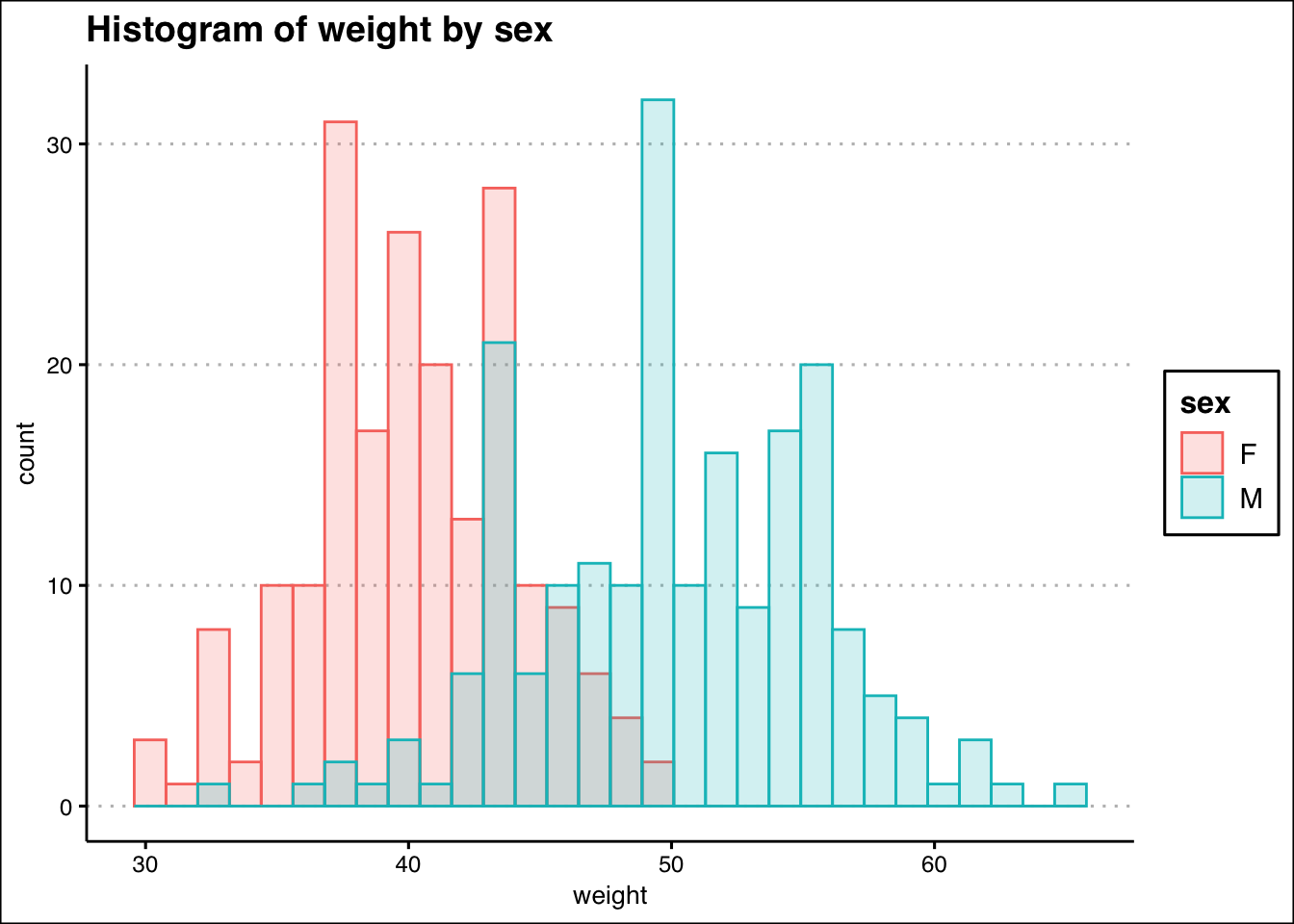
দুটি ভেরিয়েবল
যখনই দুটি সংখ্যক ভেরিয়েবল জড়িত হয়, আমরা তাদের মধ্যে সম্পর্ক বোঝার চেষ্টা করি।
mtcars%>%
ggplot(aes(x=mpg,y=hp))+geom_point(aes(colour=hp))+
labs(x="Fuel consumption (Miles per gallon)",
y="Engine power (HP)",
title = "Relationship between Engine power and fuel consumption"
)+
theme_clean()+
annotation_custom(l, xmin = 30, xmax = 35, ymin = 275, ymax = 350) +
coord_cartesian(clip = "off")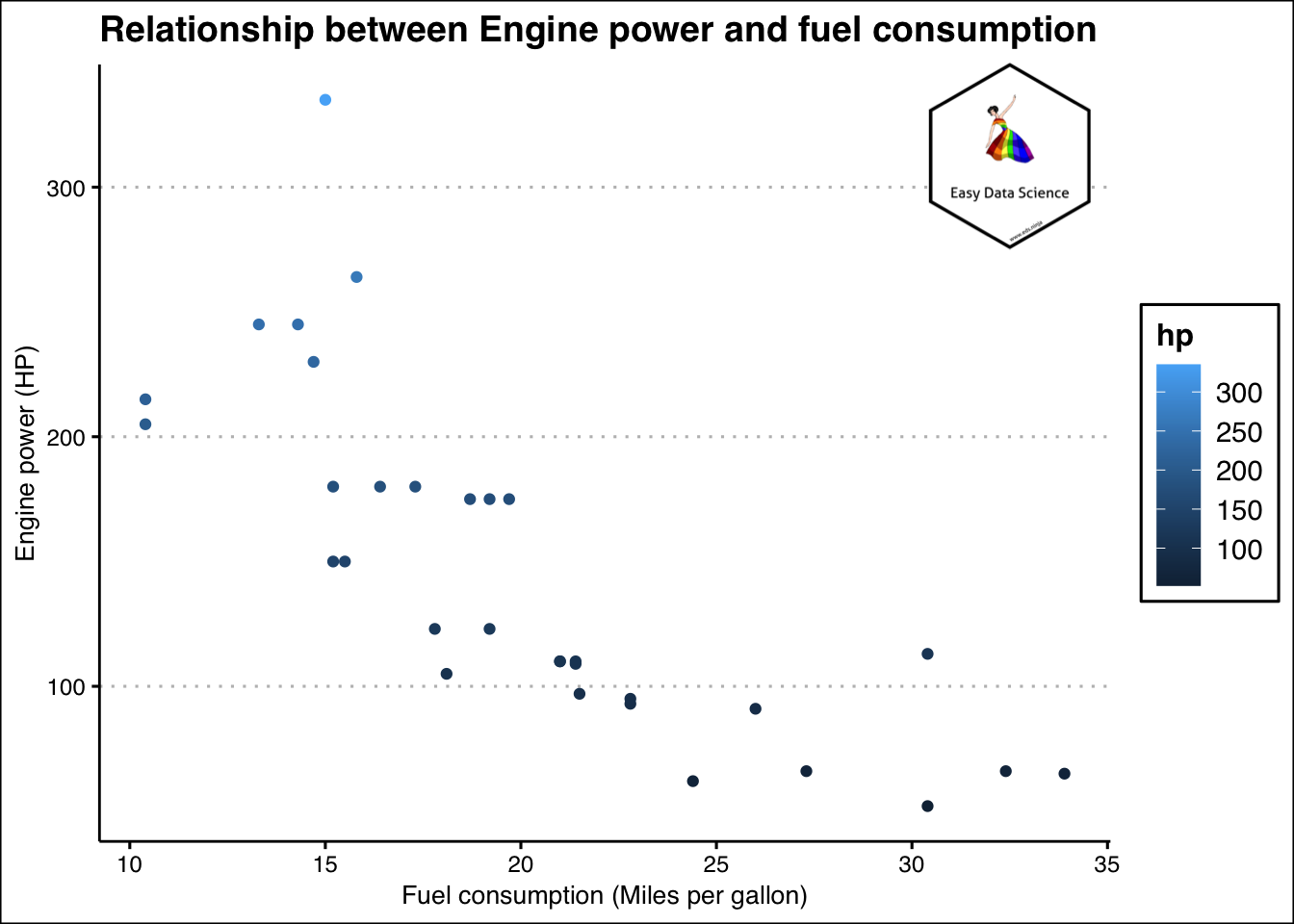
এবং যদি কোনও ভেরিয়েবলের তারিখ / বছর / মাস / সময় বা অনুরূপ হয়ে থাকে তবে আমরা প্রবণতাটি(trend) বোঝার চেষ্টা করি।
x = WDI(indicator='SL.UEM.TOTL.ZS', country=c('IN'))
x %>%
filter(is.na(x$SL.UEM.TOTL.ZS))## iso2c country SL.UEM.TOTL.ZS year
## 1 IN India NA 1990
## 2 IN India NA 1989
## 3 IN India NA 1988
## 4 IN India NA 1987
## 5 IN India NA 1986
## 6 IN India NA 1985
## 7 IN India NA 1984
## 8 IN India NA 1983
## 9 IN India NA 1982
## 10 IN India NA 1981
## 11 IN India NA 1980
## 12 IN India NA 1979
## 13 IN India NA 1978
## 14 IN India NA 1977
## 15 IN India NA 1976
## 16 IN India NA 1975
## 17 IN India NA 1974
## 18 IN India NA 1973
## 19 IN India NA 1972
## 20 IN India NA 1971
## 21 IN India NA 1970
## 22 IN India NA 1969
## 23 IN India NA 1968
## 24 IN India NA 1967
## 25 IN India NA 1966
## 26 IN India NA 1965
## 27 IN India NA 1964
## 28 IN India NA 1963
## 29 IN India NA 1962
## 30 IN India NA 1961
## 31 IN India NA 1960x<-na.omit(x)
x$year<-lubridate::ymd(x$year, truncated = 2L)
x%>%
ggplot(aes(x=year, y=SL.UEM.TOTL.ZS))+
geom_line()+
geom_point()+
labs(x="Year",
y="Unemployment Rate (% of labour force)",
title = "Uemployment Rate by year in India",
caption = "Source: World Bank")+
theme_clean() +
annotation_custom(l, xmin = 1995, xmax = 2000, ymin = 6.5, ymax = 7.0) +
coord_cartesian(clip = "off")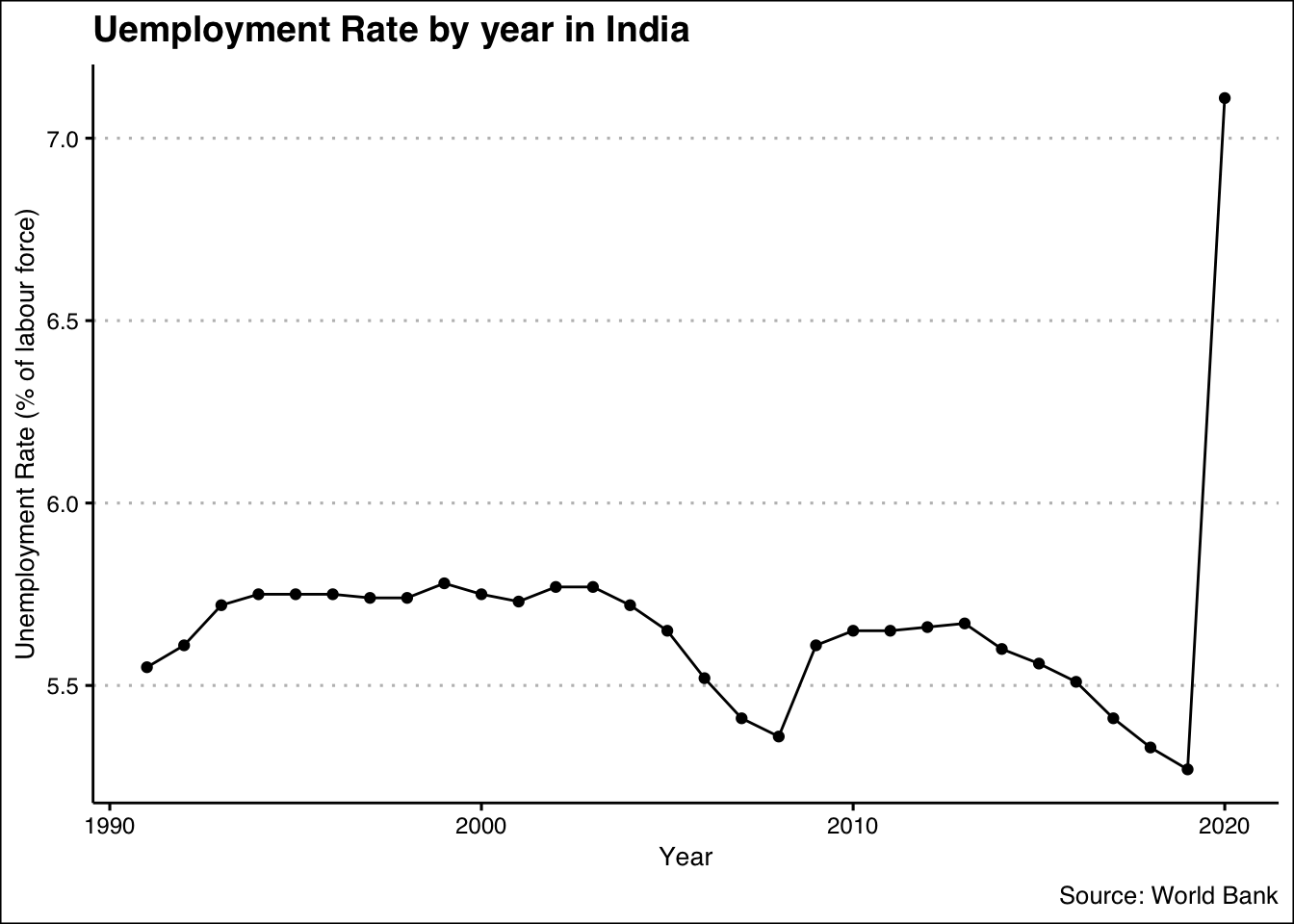
এই ব্যাখ্যা গুলির ভিডিও দেখতে চাইলে নিচের ভিডিও টি দেখতে পারেন |